I’ve had the BT Home Hub 5 for a few months now, and it keeps restarting and generally acting like a cut-price pile o’ shite. So, in an effort to monitor its shitey-ness, I figured that my home server could extract the uptime and the traffic usage every x minutes.

The HH5 is – on paper – a great little router especially as it has an Infinity modem built in meaning you can do away with the separate OpenReach white box. You can’t mount it on the wall which is annoying, and the feet are fairly useless at keeping it from toppling over, but it does output both 2.4 and 5Ghz wireless networks. One of its big downside, at least for myself, is the lack of any way of scripted monitoring (e.g. SNMP).
Monitoring
With the lack of actual monitoring tools, it was time to grab the data directly from the router’s GUI. The best place to get the data I need is to use the ‘helpdesk’ page which lists the routers vitals.
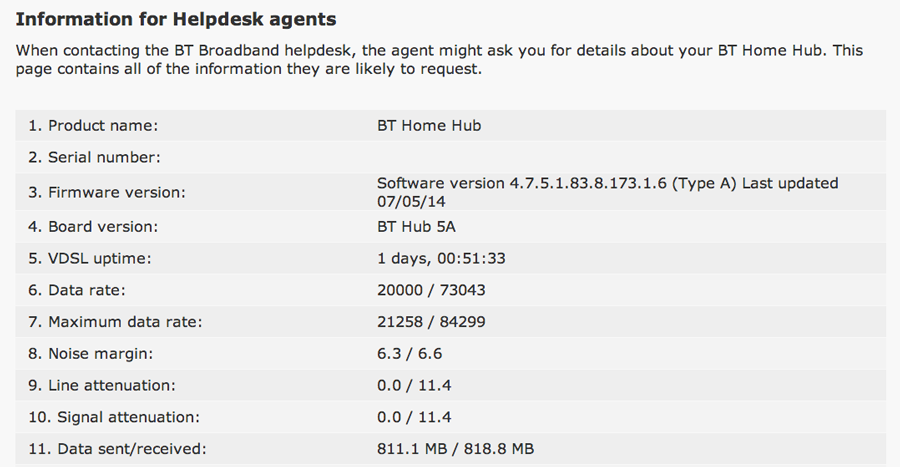
Unfortunately the accuracy will take a hit on the data sent/received figures as the units automatically scale to the amount they’re showing. For example, you can get ±0.1MB accuracy below 1GB, but only ±0.1GB above. Uptime is shown with constantly-increasing human-readable units; looking at the Javascript underneath betrays their method – an integer is hard-coded on page load with seconds of uptime and is updated with setInterval. Another function converts the number into a human-readable string and displays in the page. As cURL won’t run Javascript functions, we’ll just grab the hard-coded value.
Logging in
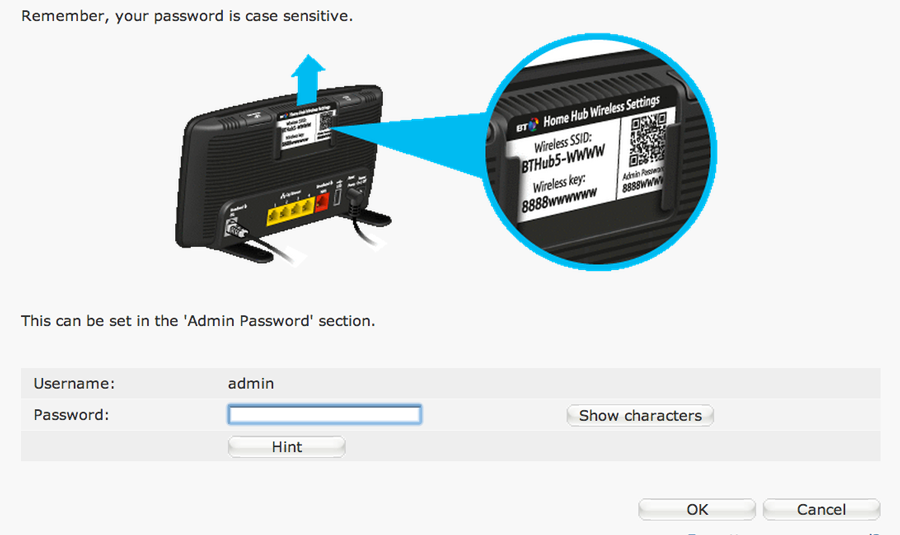
To log into a Home Hub, you have to use their strangely old-school coded GUI, which looks modern on the front-end, but the capitalised HTML tags underneath show the age of the code – I suspect that this is to increase compatibility allowing anyone, regardless of browser age, to use the control panel. The pages themselves seem to be pegged mainly towards this goal of compatibility, with GET variables being used to emulate sessions, 1×1 transparent gifs padding buttons, tables dictating the layout, and a reliance on forms to move variables around when navigating.
The login process itself only requires you to enter a password on the main screen which seems like a piece of cake to emulate. However your password is concatenated with a randomly generated auth_key and then MD5 hashed, before being added to a form in a different element. It all seemed a bit unnecessary, but it may mitigate some kind of authentication attack which I’m not aware of (EDIT: most likely to prevent a CRSF attack). The password_1879774206 element changes on every page refresh, but its not checked for anywhere so I ignored it. Wireshark was my tool of choice in finding out the exact sequence of events.
The JS function that morphs the password is connected to the submit button, as below:
[js]
function SendPassword() {
var tmp;
document.form_contents.elements[‘md5_pass’].value = document.form_contents.elements[‘password_1879774206’].value + document.form_contents.elements[‘auth_key’].value;
tmp = hex_md5(document.form_contents.elements[‘md5_pass’].value);
document.form_contents.elements[‘md5_pass’].value = tmp;
document.form_contents.elements[‘password_1879774206’].value = "";
mimic_button(‘submit_button_login_submit: ..’, 1);
}
[/js]
The mimic_button function essentially just submits the form. hex_md5 is functionally equivalent to PHP’s md5() but the JS code is much longer so its omitted for brevity.
After playing around for far too long, I found that the following process needs to happen:
- A privileged page needs to be requested, which makes the HH5 return a login form
- The
auth_keyis then exposed and a cookie ID is sent via response header to the client - The md5’d
auth_keyand password is sent via POST (with other parameters) - The original privileged page is now shown
Now, the above seems straight-forward, but took far too long to figure out. I’ve attached my code below which has a PHP class capable of retrieving any BT Home Hub 5 page.
Resources
GitHub – https://github.com/SorX14/Projects/tree/master/HomeHub5
Great, thanks for the code, it helped me with my own PHP script.
Sadly though, the Home Hub 4 has no real-time noise margins, no attenuation and no system uptime, meaning my script’s logs are quite incomplete relative to my other routers. Add to that the forced reboot every two weeks and it’s not an attractive proposition long-term.
For someone whose knowledge of coding is limited to running coding made by others in a command line on windows, how would one use the info in this project to monitor the home hub 5 blue ribbon
I’ve only put my research notes online, and not a finished product unfortunately. You would need some understanding on how to set up an always-on server and PHP scripting for this tutorial to help you I’m afraid. Its a little out of my scope to show you all of these steps; its taken me years to get here 🙂
thanks for getting back to me.
Hey man, great job with this project.
Can I ask, how would you go about using the same approach to snag a copy of all of the pages?
Minus the regex portion and doesn’t need continuous monitoring.
I’ve been struggling my ass off to achieve what you have just done using wget and haven’t had any luck but need to be able to capture the whole web interface.
Any advice would be greatly appreciated
Hey Dean,
Right, you can use `getPage()` method on `HomeHub5` to get any page, and it’ll output the HTML. Just increment a number starting from 0 and you’ll get every page. Be warned however, if you do this, it’ll eventually hit the page for reset to factory settings or restart, so you’ll have to be careful…
Using wget is possible, but you have to use cookies which makes it a bit more complicated. Have a look through `Utils.php` in the GitHub library and try to copy how I’ve done it with curl.
The regex is needed to get the auth token but you could probably do it with simple string matching.
Best of luck dude 🙂